名词解释 - 分层架构
分层架构
分层架构是一种常见的架构模式(架构风格),也叫N层架构,常见的2层C/S,B/S架构,三层架构MVC,MVP架构,操作系统的内核架构达到5层,3层以上的架构比较少见。
经典三层架构
经典三层架构自顶向下由用户界面层(User Interface Layer)、业务逻辑层(Business Logic Layer)与数据访问层(Data Access Layer)组成。

领域驱动设计提出的四层架构。
当然,DDD并不是分层架构,分层架构只是DDD的一个技术构造。
在用户界面层与业务逻辑层之间引入了新的一层,即应用层(Application Layer)。将业务逻辑层更名为领域层。将数据访问层更名为基础设施层。
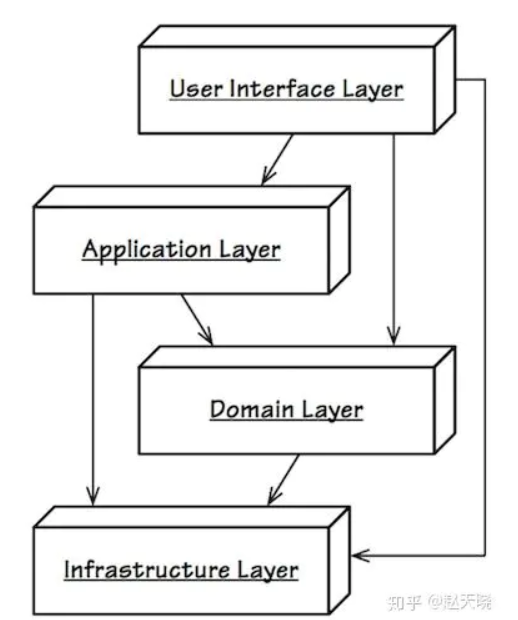
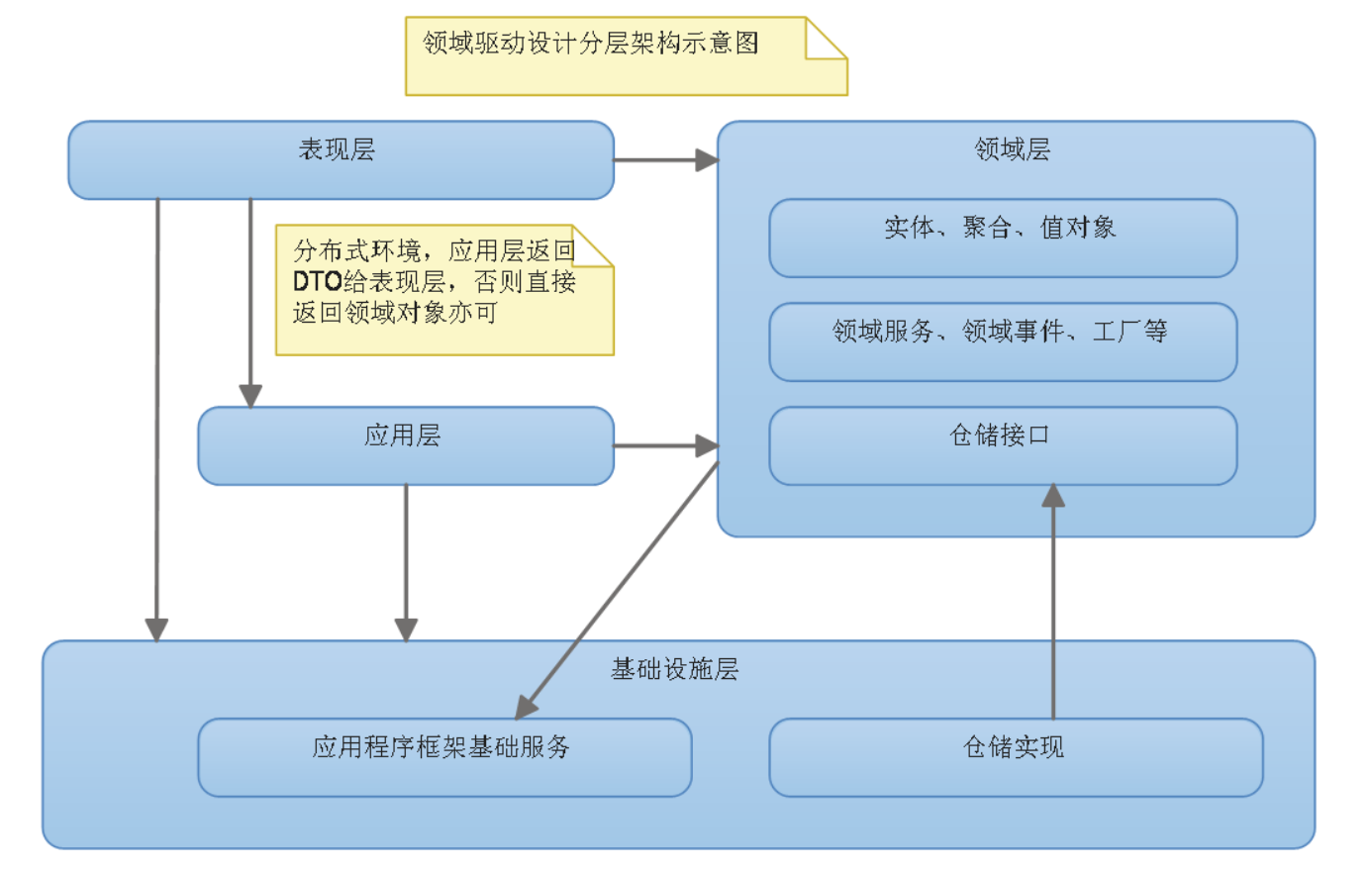
会发现领域层只依赖于应用程序框架服务,仓储采用了接口分离模式将实现和接口分离到不同的程序集,
聚合
聚合这个概念很好理解,就是包含关系。
在UML中有两种包含关系,第一种叫聚合,表示比较弱的包含关系,聚合内部的东西在外面可以直接访问。
第二种叫组合,即组成聚合,是很强的包含关系,表示外部的对象由内部的多个子对象组成,内部的子对象在外面不能直接访问,必须通过外部的对象间接引用。
DDD虽然用了聚合这个词,但它表示UML中的组成聚合,所以它把外部的对象称为根,即聚合根,要访问内部对象,必须先访问聚合根。
聚合的主要影响是显著减少仓储数量,以及集中管理高度依赖的相关实体。
把高度相关的实体内聚到一个聚合中,可以把这些依赖关系封装到一个更小的空间,外部只与聚合根打交道,与聚合内部子对象的依赖关系就会明显降低。
一个聚合对应一个仓储,而不是一个实体对象一个仓储,可以减少仓储数量,从而进一步降低依赖关系。
DDD: Domain-Driven Design
之后我开始学习EF和MVC,在刚开始接触EF的时候,我从一些博客了解到,为了发挥EF的威力,必须使用DDD进行设计。学习过程中才发现面向对象和敏捷开发才是关键
DDD的核心思想是描述如何使用面向对象的方法对业务领域建模,怎样获得更好的领域模型。虽然看了不少DDD的资料,但还是感觉它异常抽象,
TDD Test-Driven Development
Attribute
C#的attribute(特性),在java上叫作annotation(注解),是一个反射相关的功能。
补充类,字段,方法受限于语法本身不足以描述的部分。
attribute本身,就是个标记,没什么功能。
但是,别的工具、框架在做事的时候,会看相关的Attribute,做相应的处理。
就是这么起作用的。
如果我想一个类或一个属性有个注释,好方便我判断调用,怎么办,没有Attribute和注解,那只能是在配置文件里做映射,
POCO
“Plain Old C# Object”
just a normal class, no attributes describing infrastructure concerns or other responsibilities that your domain objects shouldn’t have.
In other words, they don’t derive from some special base class, nor do they return any special types for their properties.
序列化 serialization和持久化Persistence
序列化(serialization)指将数据结构或对象状态转换成可取用格式(例如存成文件,存于缓冲,或经由网络中发送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。
Serialisation is the process of turning an object into a series of bytes for transferring or storing. Saving the created objects in the sequence of bytes…
序列化格式
- 90年代后期开始推动标准序列化的协议:XML(可扩展标记语言)应用于产生人类可读的文字编码。
- JSON是一种轻量级的纯文字替代,也常用于网页应用中的客端-服务端通信。
- YAML,它包含加强序列化的功能,更“人性化”而且更扎实。这些功能包括标记资料类型,支持非层次结构式数据结构,缩进结构化资料的选项以及多种形式的标量资料引用的概念。
- 另一种可读的序列化格式是属性列表(property list)。应用在NeXTSTEP、GNUstep和macOS Cocoa环境中。
- 针对于科学使用的大量资料集合,例如气候,海洋模型和卫星数据,已经开发了特定的二进制序列化标准,例如HDF,netCDF和较旧的GRIB。
Advantages of Serialization
- To save/persist state of an object.
- To travel an object across a network.
C# Serialization & Deserialization with Example [Serializable] attribute.
DTO(DataTransfer Object)和 MO(Model Object)
数据库中的数据表示与系统中所传输的数据之间常常是不同的数据结构。一个最简单的Web服务主要分为数据访问层(DAL),业务逻辑层以及表现层三个部分。MO用于承载从DAL层读取的数据。在将数据传给客户端时,一般不会直接传输MO,而是创建一个新的对象去传输数据。用来承载在网络上所传输的数据的对象称为DTO。
在所需要的数据结构不再一样的时候,我们就需要考虑是否需要在项目中添加DTO了。
MO用来承载从数据库中读取的数据,而DTO则用来承载在网络上?所传输的数据。
贫血的DTO:DTO中只包含数据,并没有包含任何行为。
它并不擅长,甚至是不适合在业务逻辑中表示一个复杂概念。一个复杂概念常常与一些可重用的复杂逻辑关联,但这正是DTO所不能办到的。
在服务端添加一个业务逻辑表现,即BO(Business Object)。在这种情况下,MO将不会直接转化为DTO,而是转化为BO。在所有业务处理完毕并需要将数据发送给客户的时候,BO将转化为DTO以进行传输。

而在客户端,我们同样可以引入一层新的更适合于页面逻辑的数据表现。这种数据表现被称为VM(ViewModel)。
DAO则是一种组织数据库访问逻辑的一种标准模式。也就是说,与其对应的应该是Repository模式等一系列数据访问的常用方法。因此在最后,重强调DAO和MO并不是一个概念。
DAO 与 Respository
What is the difference between DAO and Repository patterns? | stackoverflow
DAO : Data access object for database operations (如CRUD)
The Data Access Object is basically an object or an interface that provides access to an underlying database or any other persistence storage.

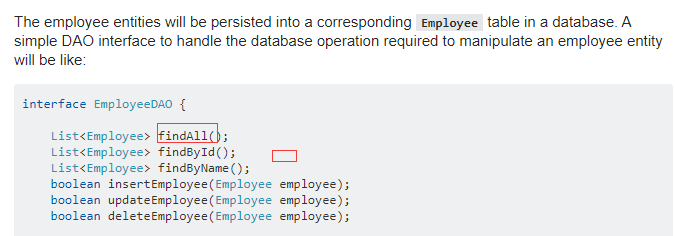
The Employee DAO will contain methods to insert/delete/update/select employee(s)
Why we use DAO
If your application uses stored procedures and database-specific code (such as generating a number sequence), how do you handle that(换数据库) in your application? You have two options:
· Rewrite your application to use SQL Server instead of Oracle (or add conditional code to handle the differences), or
· Create a layer inbetween your application logic and the data access
Its in all referred as DAO Pattern, It consist of following:
- Data Access Object Interface
- Data Access Object concrete class
- Model Object or Value Object。 This object is simple POJO
Repository vs DAO
the difference starts to show up when you have more complex apps with complex business behavior. they have different intentions in mind.
A DAO is much closer to the underlying storage , A DAO allows for a simpler way to get data from a storage, hiding the ugly queries. But the important part is that they return data as in object state.
A repository sits at a higher level. It deals with data too and hides queries and all that but, a repository deals withbusiness/domain objects. That’s the difference. use a DAO to get the data from the storage and uses that data to restore a business object.
most of the time a specialized query repository is just a DAO sending DTOs to a higher layer.
the intention of the repository is to isolate the domain objects from the database access concerns. This is the important part. The fact that the repository is using a collection-like interface, doesn’t mean you MUST treat it as a collection and you MUST have ONLY Add/Remove/Get/Find functionality. Really, it’s not a dogma and you don’t have to apply it by the letter.
programming is not a religion. But developers trend to disagree and adopt it as a religion. It’s kind annoying and it is the reason why I hate the programming community.
Back to Repository and DAO, in conclusion, they have similar intentions only that the Repository is a higher level concept dealing directly with business/domain objects, while DAO is more lower level, closer to the database/storage dealing only with data. A (micro)ORM is a DAO that is used by a Repository. For data-centric apps, a repository and DAO are interchangeable because the ‘business’ objects are simple data.
Dao (methods, insert(),update(), etc.)
repo(methods (addCustomer(), calculateDebt()) but they also could insert(),update()